Who are the top 10 radiology AI vendors, based on the number of FDA regulatory authorizations? The agency provided some clarity this week with an update to its list of authorized AI-enabled medical devices through the end of Q1 2026.
The FDA updates the list on more or less a quarterly basis, and it’s become a closely watched barometer for tracking not only the health of the AI industry but also which companies have received the greatest number of authorizations.
- As we’ve noted in the past, the list includes both standalone AI algorithms as well as medical hardware that has AI functionality embedded in it, like a mobile X-ray machine with an onboard AI feature for detecting fractures.
The updated list tracks marketing authorizations through the end of March 2026, and shows that the FDA has…
- Authorized 1,524 AI-enabled medical devices since it began keeping track in 1995, up 5.1% from Q4 2025.
- Authorized a total of 1,164 radiology devices, or 76% of all AI-enabled medical authorizations.
- In the first quarter of 2026, the FDA authorized 92 AI-enabled medical devices, or 28% more than in the fourth quarter of 2025.
- For the quarter, 69 authorizations (75%) were for radiology devices, about the same ratio as in Q4 2025 (76%).
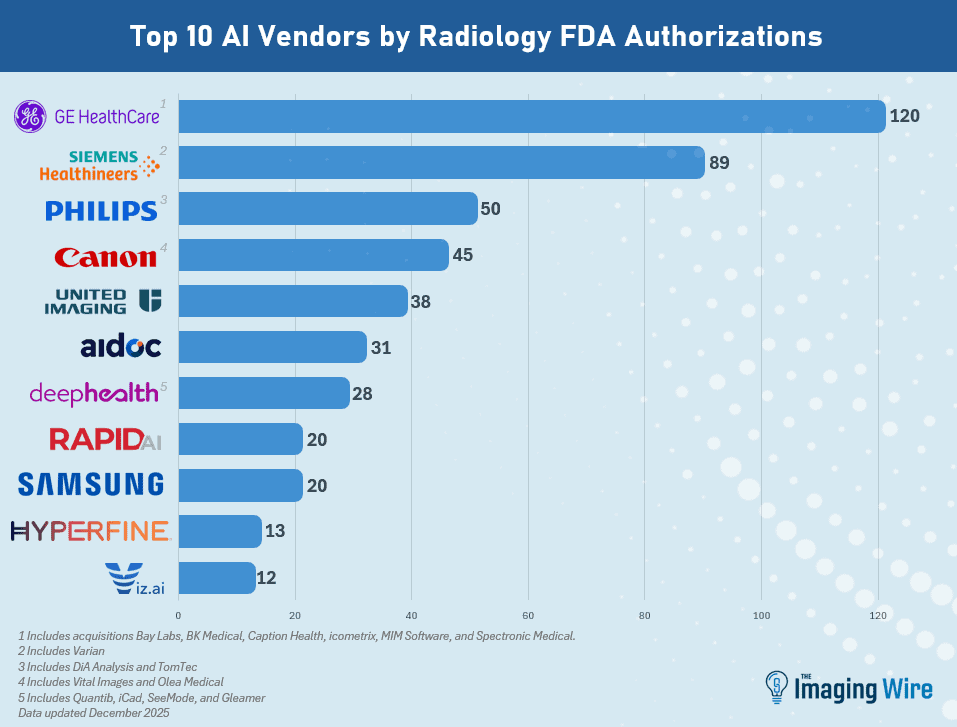
- GE HealthCare held its lead as the company with the most radiology AI authorizations at 130 (including recent acquisitions that had AI authorizations of their own).
- Next is Siemens Healthineers at 95, then Philips at 58, Canon at 48, United Imaging at 40, Aidoc at 33, and DeepHealth at 29, with all numbers including acquisitions.
- Rounding out the top 10 are Samsung (21), Rapid.ai (20), and Hyperfine (13).
The Takeaway
The FDA’s new numbers on AI marketing authorizations show that the agency is keeping pace with rapid developments in the healthcare AI industry. Indeed, the FDA is even accelerating its pace of product approvals compared to its last update, with radiology still securing the lion’s share of authorizations.